Lay of Land - Spook Author Identification¶
Lets’ start by getting a lay of land using a code first approach. Idea is to quickly jump into training NLP models using clean datasets from Kaggle. I am going to follow this wonderful kernel from Abhishek Thakur,a prolific Kaggle GM, for Spooky Author Classification Competition.
Note
Whenever we start a kaggle competition it is useful to look at evaluation metric first. Real life project are not like Kaggle. In real world following activities happen before
Identify a business problem
Clarify and refine the problem and convert the same into ML problem.
Collect relevant datasets
Preprocess and clean the dataset
Define an evaluation metric relevant for value proposition
However, when we are learning it might be useful to start with a clean dataset with evaluation criteria defined; so that we can concentrate on learning modelling skills
Imports¶
It is better to keep all imports at the top of notebook.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plot
import xgboost as xgb
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import SVC
from sklearn.decomposition import TruncatedSVD
from sklearn import metrics, pipeline
from fastai.basics import *
from nlphero.data.external import *
%matplotlib inline
data = untar_data(KAGGLEs.SPOOKY)
Simple EDA¶
First we should check out the data
| id | text | author | |
|---|---|---|---|
| 0 | id26305 | This process, however, afforded me no means of ascertaining the dimensions of my dungeon; as I might make its circuit, and return to the point whence I set out, without being aware of the fact; so perfectly uniform seemed the wall. | EAP |
| 1 | id17569 | It never once occurred to me that the fumbling might be a mere mistake. | HPL |
| 2 | id11008 | In his left hand was a gold snuff box, from which, as he capered down the hill, cutting all manner of fantastic steps, he took snuff incessantly with an air of the greatest possible self satisfaction. | EAP |
| 3 | id27763 | How lovely is spring As we looked from Windsor Terrace on the sixteen fertile counties spread beneath, speckled by happy cottages and wealthier towns, all looked as in former years, heart cheering and fair. | MWS |
| 4 | id12958 | Finding nothing else, not even gold, the Superintendent abandoned his attempts; but a perplexed look occasionally steals over his countenance as he sits thinking at his desk. | HPL |
<AxesSubplot:>
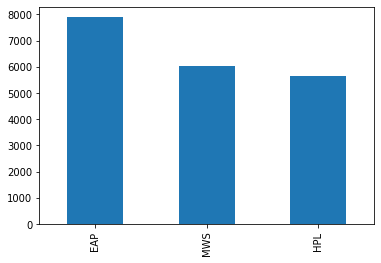
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 19579 entries, 0 to 19578
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 19579 non-null object
1 text 19579 non-null object
2 author 19579 non-null object
dtypes: object(3)
memory usage: 459.0+ KB
test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8392 entries, 0 to 8391
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 8392 non-null object
1 text 8392 non-null object
dtypes: object(2)
memory usage: 131.2+ KB
sample.head()
# print("HHH")
| id | EAP | HPL | MWS | |
|---|---|---|---|---|
| 0 | id02310 | 0.403494 | 0.287808 | 0.308698 |
| 1 | id24541 | 0.403494 | 0.287808 | 0.308698 |
| 2 | id00134 | 0.403494 | 0.287808 | 0.308698 |
| 3 | id27757 | 0.403494 | 0.287808 | 0.308698 |
| 4 | id04081 | 0.403494 | 0.287808 | 0.308698 |
So we have roughly 20k rows and about 8.4K test data (41% of size of train data). Classes are more or less equally distributed. We need to predict probabilities of different authors.
Evaluation Metric¶
For this competition, kaggle has defined multi class log loss as evaluation metric defined in link here. What does it mean ?
For each id ; we must predict probability of each author
Formulae for evaluation is defined as
def convert_multiclass(actual):
actual2 = np.zeros((actual.shape[0],predicted.shape[1]))
actual2[actual.reshape(-1,1)] = 0
for i, val in enumerate(actual):
actual2[i, val]=1
return actual2
def multiclass_logloss(actual, predicted, eps=10**-15):
y_ij = convert_multiclass(actual)
N = len(actual)
num_pij = np.clip(predicted, eps, 1-eps)
L = -(y_ij*np.log(num_pij)).sum()/N
return L
Train Test Split¶
We split and stratify based on output
x_train, y_train = train[['id','text']], train['author']
lbl_encoder = LabelEncoder()
y_train = lbl_encoder.fit_transform(y_train)
x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, stratify=y_train, test_size=0.33, random_state=42)
len(x_train), len(x_valid)
(13117, 6462)
Modelling¶
TF-IDF with Logistic Regression¶
Term frequency inverse document frequency
A good reference can be found here
{\(TF \to \text{Frequency of term in a document} \)} indicates if you are using the word too many time in a document or too little.
{\(IDF \to \text{Inverse document Frequency}\)} of a word is the measure of how significant that term is in the whole corpus.
\( TF.IDF(t, d)=W_t^{d} = TF_t^{d}\ln{\frac{N}{DF^t}}\)
\(N=\text{Total number of documents}\)
\(DF^t=\text{Number of document with term t}\)
Put simply, the higher the TF.IDF score (weight), the rarer the term and vice versa.
tfv = TfidfVectorizer(min_df=1,
max_features=None,
strip_accents="unicode",
analyzer='word',
token_pattern=r'\w{1,}',
ngram_range=(1,3),
use_idf=1,
smooth_idf=1,
sublinear_tf=1,
stop_words='english'
)
tfv
TfidfVectorizer(ngram_range=(1, 3), smooth_idf=1, stop_words='english',
strip_accents='unicode', sublinear_tf=1,
token_pattern='\\w{1,}', use_idf=1)
tfv.fit(np.concatenate([x_train['text'].values,x_valid['text'].values]))
TfidfVectorizer(ngram_range=(1, 3), smooth_idf=1, stop_words='english',
strip_accents='unicode', sublinear_tf=1,
token_pattern='\\w{1,}', use_idf=1)
x_train_tfv = tfv.transform(x_train['text'].values)
x_train_tfv
<13117x400219 sparse matrix of type '<class 'numpy.float64'>'
with 413765 stored elements in Compressed Sparse Row format>
x_valid_tfv = tfv.transform(x_valid['text'].values)
x_valid_tfv
<6462x400219 sparse matrix of type '<class 'numpy.float64'>'
with 205383 stored elements in Compressed Sparse Row format>
clf = LogisticRegression(C=1.0)
clf.fit(x_train_tfv, y_train)
LogisticRegression()
val_preds = clf.predict_proba(x_valid_tfv)
val_preds
array([[0.41254593, 0.26687746, 0.32057661],
[0.26133285, 0.13761174, 0.60105541],
[0.29159974, 0.4086124 , 0.29978786],
...,
[0.60269293, 0.18377996, 0.21352711],
[0.20320163, 0.16185855, 0.63493981],
[0.56495872, 0.15974122, 0.27530006]])
print ("logloss: %0.3f " % multiclass_logloss(y_valid, val_preds))
logloss: 0.806
def multiclass_logloss2(actual, predicted, eps=1e-15):
"""Multi class version of Logarithmic Loss metric.
:param actual: Array containing the actual target classes
:param predicted: Matrix with class predictions, one probability per class
"""
# Convert 'actual' to a binary array if it's not already:
if len(actual.shape) == 1:
actual2 = np.zeros((actual.shape[0], predicted.shape[1]))
for i, val in enumerate(actual):
actual2[i, val] = 1
actual = actual2
clip = np.clip(predicted, eps, 1 - eps)
rows = actual.shape[0]
vsota = np.sum(actual * np.log(clip))
return -1.0 / rows * vsota
print ("logloss: %0.3f " % multiclass_logloss2(y_valid, val_preds))
logloss: 0.806
CountVector with Logistic Regression¶
CountVectorizer - Frequency of different words
cv = CountVectorizer(analyzer='word',
token_pattern=r'\w{1,}',
ngram_range=(1,3),
stop_words='english'
)
cv
CountVectorizer(ngram_range=(1, 3), stop_words='english',
token_pattern='\\w{1,}')
cv.fit(np.concatenate([x_train['text'].values,x_valid['text'].values]))
CountVectorizer(ngram_range=(1, 3), stop_words='english',
token_pattern='\\w{1,}')
x_train_cv = cv.transform(x_train['text'].values)
x_train_cv
<13117x400266 sparse matrix of type '<class 'numpy.int64'>'
with 413776 stored elements in Compressed Sparse Row format>
x_valid_cv = cv.transform(x_valid['text'].values)
x_valid_cv
<6462x400266 sparse matrix of type '<class 'numpy.int64'>'
with 205395 stored elements in Compressed Sparse Row format>
clf = LogisticRegression(C=1.0)
clf.fit(x_train_cv, y_train)
clf
LogisticRegression()
val_preds = clf.predict_proba(x_valid_cv)
val_preds
array([[0.53572102, 0.11567325, 0.34860574],
[0.03049094, 0.00427 , 0.96523906],
[0.33594102, 0.3222241 , 0.34183488],
...,
[0.97113843, 0.01189312, 0.01696845],
[0.05768433, 0.02785335, 0.91446231],
[0.8622879 , 0.020955 , 0.1167571 ]])
print ("logloss: %0.3f " % multiclass_logloss2(y_valid, val_preds))
logloss: 0.557
MultinomialNB¶
clf = MultinomialNB()
clf.fit(x_train_tfv, y_train)
MultinomialNB()
val_preds = clf.predict_proba(x_valid_tfv)
val_preds
array([[0.43479056, 0.2630958 , 0.30211364],
[0.33038311, 0.16973709, 0.4998798 ],
[0.37577295, 0.34463046, 0.27959659],
...,
[0.54395868, 0.18701702, 0.2690243 ],
[0.27495975, 0.18696675, 0.5380735 ],
[0.56420466, 0.16682221, 0.26897313]])
print ("logloss: %0.3f " % multiclass_logloss(y_valid, val_preds))
logloss: 0.853
clf = MultinomialNB()
clf.fit(x_train_cv, y_train)
val_preds = clf.predict_proba(x_valid_cv)
print ("logloss: %0.3f " % multiclass_logloss(y_valid, val_preds))
logloss: 0.467
def check_score(clf, vectorizer,
x_train=x_train, x_valid=x_valid,
y_train=y_train, y_valid=y_valid):
vectorizer.fit(np.concatenate([x_train['text'].values,
x_valid['text'].values]))
x_train_vect = vectorizer.transform(x_train['text'].values)
x_valid_vect = vectorizer.transform(x_valid['text'].values)
clf.fit(x_train_vect, y_train)
val_preds = clf.predict_proba(x_valid_vect)
mcll = multiclass_logloss(y_valid, val_preds)
return mcll
clf = MultinomialNB()
vectorizer = CountVectorizer(analyzer='word',
token_pattern=r'\w{1,}',
ngram_range=(1,3),
stop_words='english'
)
score = check_score(clf, vectorizer)
print ("logloss: %0.3f " % score)
logloss: 0.467
score = check_score(clf, tfv)
print ("logloss: %0.3f " % score)
logloss: 0.853
SVD¶
svd = TruncatedSVD(n_components=120)
svd.fit(x_train_cv)
TruncatedSVD(n_components=120)
xtrain_svd = svd.transform(x_train_cv)
xvalid_svd = svd.transform(x_valid_cv)
scl = StandardScaler()
scl.fit(xtrain_svd)
StandardScaler()
xtrain_svd_scl = scl.transform(xtrain_svd)
xvalid_svd_scl = scl.transform(xvalid_svd)
clf = SVC(C=1.0, probability=True) # since we need probabilities
clf.fit(xtrain_svd_scl, y_train)
val_preds = clf.predict_proba(xvalid_svd_scl)
print("logloss: %0.3f " % multiclass_logloss(y_valid, val_preds))
logloss: 0.787
x_train_tfv.tocsc()
<13117x400219 sparse matrix of type '<class 'numpy.float64'>'
with 413765 stored elements in Compressed Sparse Column format>
x_train_tfv
<13117x400219 sparse matrix of type '<class 'numpy.float64'>'
with 413765 stored elements in Compressed Sparse Row format>
XGBoost¶
CountVectorizer¶
clf = xgb.XGBClassifier(max_depth=7,
n_estimators=200,
colsample_bytree=0.8,
subsample=0.8,
nthread=10,
learning_rate=0.1)
vectorizer = CountVectorizer(analyzer='word',
token_pattern=r'\w{1,}',
ngram_range=(1,3),
stop_words='english'
)
score = check_score(clf, vectorizer)
print ("logloss: %0.3f " % score)
logloss: 0.776
Tf-idfVectorizer¶
clf = xgb.XGBClassifier(max_depth=7,
n_estimators=200,
colsample_bytree=0.8,
subsample=0.8,
nthread=10,
learning_rate=0.1)
vectorizer = TfidfVectorizer(min_df=1,
max_features=None,
strip_accents="unicode",
analyzer='word',
token_pattern=r'\w{1,}',
ngram_range=(1,3),
use_idf=1,
smooth_idf=1,
sublinear_tf=1,
stop_words='english'
)
score = check_score(clf, vectorizer)
print ("logloss: %0.3f " % score)
logloss: 0.787
SVD Transformation¶
clf = xgb.XGBClassifier(max_depth=7,
n_estimators=200,
colsample_bytree=0.8,
subsample=0.8,
nthread=10,
learning_rate=0.1)
clf.fit(xtrain_svd, y_train)
val_preds = clf.predict_proba(xvalid_svd)
score = multiclass_logloss(y_valid, val_preds)
print ("logloss: %0.3f " % score)
logloss: 0.805
Grid Search¶
Doing Grid Search using Logistic Regression
# mll_scorer = metrics.make_scorer?
mll_scorer = metrics.make_scorer(multiclass_logloss,
greater_is_better=False,
needs_proba=True)
mll_scorer
make_scorer(multiclass_logloss, greater_is_better=False, needs_proba=True)
svd = TruncatedSVD()
scl = StandardScaler()
lr_model = LogisticRegression()
clf = pipeline.Pipeline([
('svd', svd),
('scl', scl),
('lr', lr_model)
])
clf
Pipeline(steps=[('svd', TruncatedSVD()), ('scl', StandardScaler()),
('lr', LogisticRegression())])
param_grid = {
'svd__n_components':[120, 180],
'lr__C': [0.1, 1.0, 10],
'lr__penalty':['l1','l2']
}
param_grid
{'svd__n_components': [120, 180],
'lr__C': [0.1, 1.0, 10],
'lr__penalty': ['l1', 'l2']}
model = GridSearchCV(estimator=clf,
param_grid=param_grid,
scoring=mll_scorer,
verbose=10,
n_jobs=-1,
iid=True,
refit=True,
cv=2
)
model
GridSearchCV(cv=2,
estimator=Pipeline(steps=[('svd', TruncatedSVD()),
('scl', StandardScaler()),
('lr', LogisticRegression())]),
iid=True, n_jobs=-1,
param_grid={'lr__C': [0.1, 1.0, 10], 'lr__penalty': ['l1', 'l2'],
'svd__n_components': [120, 180]},
scoring=make_scorer(multiclass_logloss, greater_is_better=False, needs_proba=True),
verbose=10)
model.fit(x_train_tfv, y_train)
model
Fitting 2 folds for each of 12 candidates, totalling 24 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 32 concurrent workers.
[Parallel(n_jobs=-1)]: Done 1 tasks | elapsed: 1.5min
[Parallel(n_jobs=-1)]: Done 3 out of 24 | elapsed: 1.5min remaining: 10.7min
[Parallel(n_jobs=-1)]: Done 6 out of 24 | elapsed: 1.6min remaining: 4.7min
[Parallel(n_jobs=-1)]: Done 9 out of 24 | elapsed: 1.6min remaining: 2.7min
[Parallel(n_jobs=-1)]: Done 12 out of 24 | elapsed: 1.6min remaining: 1.6min
[Parallel(n_jobs=-1)]: Done 15 out of 24 | elapsed: 2.2min remaining: 1.3min
[Parallel(n_jobs=-1)]: Done 18 out of 24 | elapsed: 2.2min remaining: 43.9s
[Parallel(n_jobs=-1)]: Done 21 out of 24 | elapsed: 2.2min remaining: 18.9s
[Parallel(n_jobs=-1)]: Done 24 out of 24 | elapsed: 2.2min remaining: 0.0s
[Parallel(n_jobs=-1)]: Done 24 out of 24 | elapsed: 2.2min finished
/home/ubuntu/anaconda3/envs/nlphero/lib/python3.8/site-packages/sklearn/model_selection/_search.py:847: FutureWarning: The parameter 'iid' is deprecated in 0.22 and will be removed in 0.24.
warnings.warn(
GridSearchCV(cv=2,
estimator=Pipeline(steps=[('svd', TruncatedSVD()),
('scl', StandardScaler()),
('lr', LogisticRegression())]),
iid=True, n_jobs=-1,
param_grid={'lr__C': [0.1, 1.0, 10], 'lr__penalty': ['l1', 'l2'],
'svd__n_components': [120, 180]},
scoring=make_scorer(multiclass_logloss, greater_is_better=False, needs_proba=True),
verbose=10)
print(f"Best Score: {model.best_score_:.3}")
print("Best parameters set:")
best_parameters = model.best_estimator_.get_params()
for param_name in sorted(param_grid.keys()):
print(param_name, best_parameters[param_name])
Best Score: -0.792
Best parameters set:
lr__C 0.1
lr__penalty l2
svd__n_components 180
model = GridSearchCV(estimator=clf,
param_grid=param_grid,
scoring=mll_scorer,
verbose=10,
n_jobs=-1,
iid=True,
refit=True,
cv=2)
model.fit(x_train_tfv, y_train)
print(f"Best Score: {model.best_score_:.3}")
print("Best parameters set:")
best_parameters = model.best_estimator_.get_params()
for param_name in sorted(param_grid.keys()):
print(param_name, best_parameters[param_name])
Fitting 2 folds for each of 12 candidates, totalling 24 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 32 concurrent workers.
[Parallel(n_jobs=-1)]: Done 1 tasks | elapsed: 1.4min
[Parallel(n_jobs=-1)]: Done 3 out of 24 | elapsed: 1.5min remaining: 10.3min
[Parallel(n_jobs=-1)]: Done 6 out of 24 | elapsed: 1.5min remaining: 4.6min
[Parallel(n_jobs=-1)]: Done 9 out of 24 | elapsed: 1.6min remaining: 2.7min
[Parallel(n_jobs=-1)]: Done 12 out of 24 | elapsed: 1.6min remaining: 1.6min
[Parallel(n_jobs=-1)]: Done 15 out of 24 | elapsed: 2.2min remaining: 1.3min
[Parallel(n_jobs=-1)]: Done 18 out of 24 | elapsed: 2.2min remaining: 43.9s
[Parallel(n_jobs=-1)]: Done 21 out of 24 | elapsed: 2.2min remaining: 18.9s
[Parallel(n_jobs=-1)]: Done 24 out of 24 | elapsed: 2.2min remaining: 0.0s
[Parallel(n_jobs=-1)]: Done 24 out of 24 | elapsed: 2.2min finished
/home/ubuntu/anaconda3/envs/nlphero/lib/python3.8/site-packages/sklearn/model_selection/_search.py:847: FutureWarning: The parameter 'iid' is deprecated in 0.22 and will be removed in 0.24.
warnings.warn(
Best Score: -0.789
Best parameters set:
lr__C 10
lr__penalty l2
svd__n_components 180